ArrayList 遍历删除
list的遍历分为3种:
- 普通遍历,
for(int i=0;i<list.size();i++) - 增强for循环,
for(Object x:list) - iterator遍历,
Iterator<String> it = list.iterator(); while(it.hasNext()){}
同时ArrayList和线程安全的CopyOnWriteArrayList不同遍历下变现也不同,下面分类展示各种情况。
list的遍历分为3种:
for(int i=0;i<list.size();i++)for(Object x:list)Iterator<String> it = list.iterator(); while(it.hasNext()){}同时ArrayList和线程安全的CopyOnWriteArrayList不同遍历下变现也不同,下面分类展示各种情况。
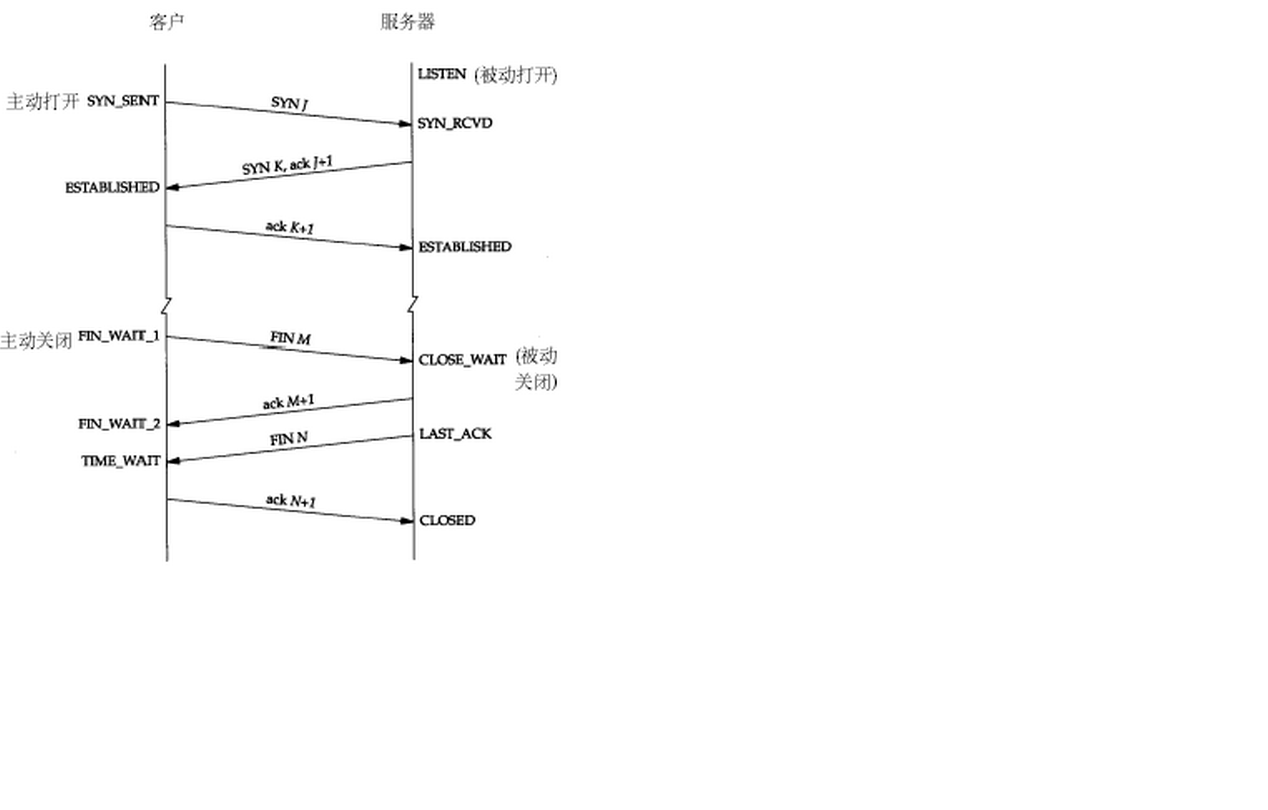
建立TCP需要三次握手才能建立,而断开连接则需要四次挥手。整个过程如下图所示:
JDK 8 是自JDK 5以来,Oracle对JDK做出的最重大的更新,这个版本中包含了语言、编译器、库、工具、JVM等多种新特性。针对我们平时常用的一些场景,接下来将介绍JDK 8中的新特性。
Lambda的设计者们为了让现有的功能与Lambda表达式良好兼容,考虑了很多方法,于是产生了函数接口这个概念,所以我们先讲函数式接口。
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
1 |
|
Maven 是 Apache 下的一个纯 Java 开发的项目管理工具,可以对 Java 项目进行构建、依赖管理。
Maven 提倡使用一个共同的标准目录结构,Maven 使用约定优于配置的原则,大家尽可能的遵守这样的目录结构。如下所示:
| 目录 | 作用 |
|---|---|
| ${basedir} | 存放pom.xml和所有的子目录 |
| ${basedir}/src/main/java | 项目的java源代码 |
| ${basedir}/src/main/resources | 项目的资源,比如说property文件,springmvc.xml |
| ${basedir}/src/test/java | 项目的测试类,比如说Junit代码 |
| ${basedir}/src/test/resources | 测试用的资源 |
| ${basedir}/src/main/webapp/WEB-INF | web应用文件目录,web项目的信息,比如存放web.xml、本地图片、jsp视图页面 |
| ${basedir}/target | 打包输出目录 |
| ${basedir}/target/classes | 编译输出目录 |
| ${basedir}/target/test-classes | 测试编译输出目录 |
图解SpringMVC执行流程:
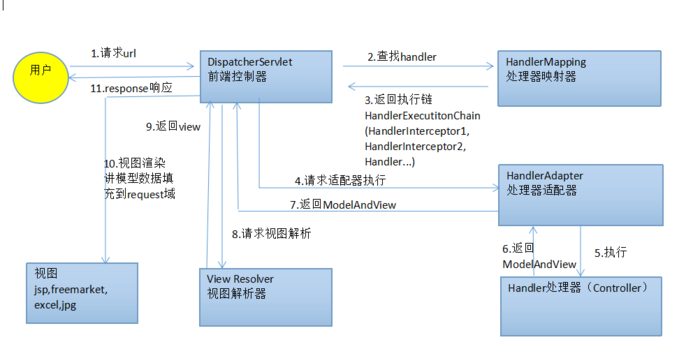
SpringMVC执行流程:
在Java对象的创建时,单例模式使用尤其多,同时也是个面试必问的基础题。很多时候面试官想问的无非是懒汉式的双重检验锁。但是其实还有两种更加直观高效的写法,也是《Effective Java》中所推荐的写法。
1 | public class Singleton { |
这种写法仍然使用JVM本身机制保证了线程安全问题;由于 SingletonHolder 是私有的,除了 getInstance() 之外没有办法访问它,因此它是懒汉式的;同时读取实例的时候不会进行同步,没有性能缺陷;也不依赖 JDK 版本。
Semaphore类位于java.util.concurrent包下,它提供了2个构造器:
1 | //参数permits表示许可数目,即同时可以允许多少线程进行访问 |
Semaphore类中比较重要的几个方法,首先是acquire()、release()方法:
acquire()方法会被阻塞,如果想立即得到执行结果,可以使用下面几个方法:
1 | //尝试获取一个许可,若获取成功,则立即返回true,若获取失败,则立即返回false |
线程是稀缺资源,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以重复使用。
可以根据系统的承受能力,调整线程池中工作线程的数量,防止因为消耗过多内存导致服务器崩溃。
当我们把一个Runnable交给线程池去执行的时候,这个线程池处理的流程是这样的:
当队列和线程池都满了的时候,再有新的任务到达,就必须要有一种办法来处理新来的任务。Java线程池中提供了以下四种策略: